이번 포스팅에서는 node.js에서 OCR(Optical character recognition) 이 가능한 패키지를 소개하고자 한다.
사용해볼 패키지는 tesseract 로 해당 패키지의 두가지 방법을 소개할 것인데, 필자는 후자의 방법을 더 추천한다.
(첫번째 방법은 디렉토리의 이미지파일을 잘 읽어 오지 못한다..)
그래도 url을 통한 인식은 좋은 편이니 본인의 프로젝트에 맞게 잘 선택하기 바란다.
1. tesseract에 대한 소개

https://openbase.com/categories/js/best-nodejs-ocr-libraries
10 Best Node.js OCR Libraries in 2021 | Openbase
A comparison of the 10 Best Node.js OCR Libraries in 2021: tesseractocr, tesseract, penteract, okrabyte, node-tesseract-ocr and more
openbase.com
node에서 사용하기 좋은 10가지 ocr 라이브러리를 보면 tesseract가 꽤 많이 보인다.
구글에서 06년부터 지원하기 시작했다는데,
현재 버전 4에서는 116개의 언어를 지원하고, LSTM기반 OCR엔진을 적용했다고 한다.
여러 플랫폼에서 지원하기 때문에 확장성 면에서는 뛰어나며, 최근 패키지들이 3개월, 7개월전에 업데이트 되는 것으로 보아 업데이트도 꾸준히 진행하고 있는 것으로 보인다.
그럼 바로 tesseract에 대한 사용법을 알아보도록 하자.
2-1. tesseract.js
먼저 사전에 node폴더 내에서
$ npm install tesseract.js 를 실행해줘야 한다.
잘 설치 되었는지 확인한 뒤 해당 예제코드를 돌려주면 된다.
import { createWorker } from 'tesseract.js';
const worker = createWorker({
logger: m => console.log(m)
});
(async () => {
await worker.load();
await worker.loadLanguage('eng'); //추출대상 언어
await worker.initialize('eng'); //추출대상 언어
const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png');
console.log(text);
await worker.terminate();
})();이정도의 인식률이라고 보시면 될 듯 하다.
위의 오류메시지는 chi_tra 트레이닝 데이터가 누락이 되었다는 소리인데, 해당 패키지의 경우 npm 명령어로 설치하면
다음과 같이 훈련데이터가 다운된다. 필자는 chi_tra가 중국어라 필요 없을 것 같아서 지웠는데 한글대상으로 추출돌리면 계속 뜬다.. 실제로 결과를 보는데에는 크게 문제가 없다.
또한 인식언어는 '+' 를 사용하여 2개언어를 지정할 수도 있다.
모 악보를 인식해보니 영어제목과 한글 두개를 인식하는 모습을 볼 수 있다.
2.2 node-tesseract
이번에 설명할 것은 node-tesseract인데, 이것이 앞의 것보다 좀 더 사용하기 편한 느낌이라 이것또한 설명한다.
해당 패키지는 파일경로도 잘 인식해서 보다 더 편리하게 사용 가능하다.
먼저
$ sudo apt-get install tesseract-ocr
이후 프로젝트 폴더에 접근해서
$ npm install node-tesseract-ocr
여기가 중요한데,
$ tesseract --list-langs
를 구동해보고 내가 원하는 언어 (예를 들어 kor) 이 없다면 따로 설치를 해줘야 한다.
이 부분을 확인을 안하고 이후 코드를 구동시키면,
error opening data file /usr/share/tesseract-ocr/4.00/tessdata/ko.traineddata
다음과 같은 오류가 뜨면서 실행이 불가능 하다.
이때는
$ sudo apt-get install tesseract-ocr-kor을 실행하고,
다시 tesseract --list-langs를 실행하면 kor이 존재하는 것을 확인 할 수 있다.
*참고) 여기서 설치하는 tesseract버전은 21-12-04 기준으로 4버전이다.

예제코드
const tesseract = require("node-tesseract-ocr")
const config = {
lang: "kor+eng",
oem: 1,
psm: 3,
}
tesseract
.recognize("http://www.musicscore.co.kr/sample/samp7ys7f3ij9wkjid8eujfhsiud843dsijfowejfisojf3490fi0if0sjk09jkr039uf90u/8u4ojsjdjf430foeid409ijef923jerojfgojdofj894jjdsf934f90f40ufj390rfjds/sample_63000/sample_3zICj22vAF2018111620349.jpg", config)
.then((text) => {
console.log("Result:", text)
})
.catch((error) => {
console.log(error.message)
})
다음과 같은 코드이며,
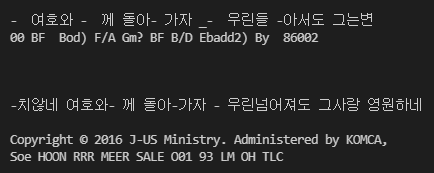
아까와 같은 악보를 대상으로 추출을 진행하였다.


위에꺼가 1번
아래꺼가 2번이다.
선택은 여러분의 몫으로.. ㅎㅎ
2번의 코드는 로컬에 저장된 경로도 잘 인식한다.
tesseract
.recognize("pic/pic.PNG", config)
.then((text) => {
console.log("Result:", text)
})
.catch((error) => {
console.log(error.message)
})
3. 정리
이렇게 OCR 라이브러리에대해 가볍게 설명해 보았다. 부디 이 글이 다른 이에게 읽혀 좋은 프로젝트의 일부가 되었으면 한다.
'Node.js' 카테고리의 다른 글
| [TypeScript] 타입스크립트는? 용도와 프로젝트 코드 변경 (1) (0) | 2022.03.04 |
|---|---|
| [Typescript] Typescript 설치 (0) | 2022.02.25 |
| [Node.js] 사이트에서 네이버 아이디로 로그인 구현 (passport-naver) (0) | 2021.12.15 |
| [Node.js] 우분투에 Node.js 설치 (0) | 2021.11.27 |